基于Yandex NLP课程的Seq2Seq模型实践指南
2025-07-06 06:26:00作者:宣利权Counsellor
概述
本文将介绍如何使用TensorFlow 2.0构建一个基础的编码器-解码器(Seq2Seq)模型,并将其应用于机器翻译任务。我们将使用俄语到英语的酒店描述数据集作为示例,通过实践理解Seq2Seq模型的核心概念和实现细节。
Seq2Seq模型简介
Seq2Seq模型是一种将序列转换为序列的深度学习架构,广泛应用于:
- 机器翻译和对话系统
- 图像描述生成(卷积编码器+循环解码器)
- 根据描述生成图像(循环编码器+卷积解码器)
- 字形到音素转换
数据预处理
任务描述
我们将处理俄语到英语的酒店和旅馆描述翻译任务。这个任务规模适中,不需要GPU也能在合理时间内完成训练。
分词与BPE编码
直接使用单词级别表示会遇到词汇量过大的问题,而纯字符级别表示则处理效率低下。我们采用折中的方法——字节对编码(BPE):
- 使用WordPunctTokenizer进行初始分词
- 应用BPE算法,迭代合并最常见的字符对
- 最终得到8000个符号的词汇表
BPE的优势在于:
- 高频词保持为单个token
- 低频词被拆分为子词或字符
- 平衡了词汇表大小和序列长度
from nltk.tokenize import WordPunctTokenizer
from subword_nmt.learn_bpe import learn_bpe
from subword_nmt.apply_bpe import BPE
tokenizer = WordPunctTokenizer()
def tokenize(x):
return ' '.join(tokenizer.tokenize(x.lower()))
# 学习BPE规则
for lang in ['en', 'ru']:
learn_bpe(open(f'train.{lang}'), open(f'bpe_rules.{lang}', 'w'), num_symbols=8000)
bpe[lang] = BPE(open(f'bpe_rules.{lang}'))
词汇表构建
我们需要构建词汇表来实现词与ID之间的相互转换:
from utils import Vocab
# 加载BPE处理后的数据
data_inp = np.array(open('./train.bpe.ru').read().split('\n'))
data_out = np.array(open('./train.bpe.en').read().split('\n'))
# 创建词汇表
inp_voc = Vocab.from_lines(train_inp)
out_voc = Vocab.from_lines(train_out)
词汇表支持以下操作:
to_matrix: 将文本行转换为ID矩阵to_lines: 将ID矩阵转换回文本
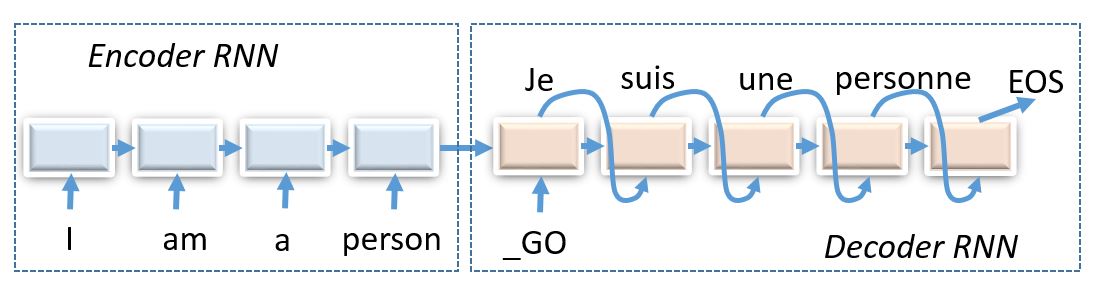
基础Seq2Seq模型实现
模型架构
我们的基础模型包含以下组件:
- 词嵌入层(Embedding)
- GRU编码器
- GRU解码器
- 输出logits层
class BasicModel(L.Layer):
def __init__(self, inp_voc, out_voc, emb_size=64, hid_size=128):
super().__init__()
self.inp_voc, self.out_voc = inp_voc, out_voc
self.hid_size = hid_size
# 嵌入层
self.emb_inp = L.Embedding(len(inp_voc), emb_size)
self.emb_out = L.Embedding(len(out_voc), emb_size)
# 编码器和解码器
self.enc0 = L.GRUCell(hid_size)
self.dec_start = L.Dense(hid_size)
self.dec0 = L.GRUCell(hid_size)
self.logits = L.Dense(len(out_voc))
编码过程
编码器将输入序列转换为固定大小的上下文向量:
def encode(self, inp, **flags):
inp_emb = self.emb_inp(inp)
batch_size = inp.shape[0]
# 创建掩码(处理变长序列)
mask = infer_mask(inp, self.inp_voc.eos_ix, dtype=tf.bool)
# 初始化状态
state = [tf.zeros((batch_size, self.hid_size), tf.float32)]
# 逐步处理输入序列
for i in tf.range(inp_emb.shape[1]):
output, next_state = self.enc0(inp_emb[:, i], state)
state = [
tf.where(
tf.tile(mask[:, i, None], [1, next_tensor.shape[1]]),
next_tensor, tensor
) for tensor, next_tensor in zip(state, next_state)
]
dec_start = self.dec_start(state[0])
return [dec_start]
解码过程
解码器根据编码器的输出和之前生成的token逐步生成翻译结果:
def decode_step(self, prev_state, prev_tokens, **flags):
# 实现单步解码
<YOUR CODE HERE>
return new_dec_state, output_logits
def decode(self, initial_state, out_tokens, **flags):
# 完整解码过程(训练时使用)
state = initial_state
batch_size = out_tokens.shape[0]
# 初始logits(总是预测BOS)
first_logits = tf.math.log(
tf.one_hot(tf.fill([batch_size], self.out_voc.bos_ix),
len(self.out_voc)) + 1e-30)
outputs = [first_logits]
for i in tf.range(out_tokens.shape[1] - 1):
state, logits = self.decode_step(state, out_tokens[:, i])
outputs.append(logits)
return tf.stack(outputs, axis=1)
损失函数计算
我们使用交叉熵损失,需要注意:
- 只计算到第一个EOS标记
- 按实际序列长度(不包括padding)进行归一化
def compute_loss(model, inp, out, **flags):
inp, out = map(tf.convert_to_tensor, [inp, out])
targets_1hot = tf.one_hot(out, len(model.out_voc), dtype=tf.float32)
mask = infer_mask(out, out_voc.eos_ix) # [batch_size, out_len]
# 模型输出 [batch_size, out_len, num_tokens]
logits_seq = <YOUR CODE HERE>
# 所有token在所有步骤的log概率 [batch_size, out_len, num_tokens]
logprobs_seq = <YOUR CODE HERE>
# 正确输出的log概率 [batch_size, out_len]
logp_out = tf.reduce_sum(logprobs_seq * targets_1hot, axis=-1)
# 对mask==1的token计算平均交叉熵
return <YOUR CODE HERE> # 标量
模型评估:BLEU分数
BLEU(Bilingual Evaluation Understudy)是机器翻译的常用评估指标:
- 计算预测n-gram在参考翻译中出现的比例(n=1,2,3,4)
- 计算几何平均值
- 对短于参考的翻译施加惩罚
from nltk.translate.bleu_score import corpus_bleu
def compute_bleu(model, inp_lines, out_lines, bpe_sep='@@ ', **flags):
translations, _ = model.translate_lines(inp_lines, **flags)
translations = [line.replace(bpe_sep, '') for line in translations]
return corpus_bleu(
[[ref.split()] for ref in out_lines],
[trans.split() for trans in translations],
smoothing_function=<...>
)
总结
本文详细介绍了如何使用TensorFlow 2.0实现一个基础的Seq2Seq模型,包括:
- 数据预处理和BPE编码
- 词汇表构建
- 编码器-解码器架构实现
- 损失函数计算
- BLEU评估指标
这个基础模型可以进一步扩展,例如:
- 添加注意力机制
- 使用更强大的Transformer架构
- 实现集束搜索解码
- 加入子词正则化技术
希望这篇指南能帮助你理解Seq2Seq模型的核心概念和实现细节,并为更复杂的NLP任务打下基础。

